
Introduction
Text to speech (TTS) technology has transformed the way we interact with digital content, making information accessible to a wider audience and enhancing our everyday lives. In this article, we will delve into the rich history of text to speech technology, explore the various methods of TTS synthesis, discuss the challenges and limitations it has faced, and peek into the promising future of this evolving technology.
The History of Text to Speech Technology
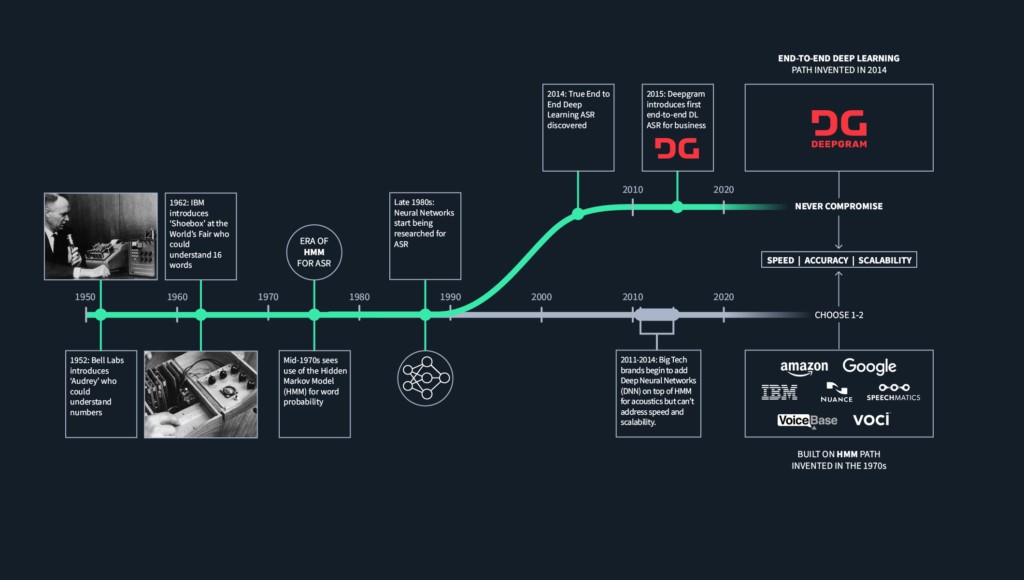
The origins of text to speech technology can be traced back to early attempts to convert written text into audible speech. Here is a brief timeline of its development:
- Early Concepts (8th Century): The earliest recorded idea of mechanical text to speech synthesis can be found in the works of Arab scientist Al-Jazari, who described a device that could simulate human speech.
- Voder (1939): Developed by Homer Dudley at Bell Labs, the Voder was one of the first electronic speech synthesizers. It required highly trained operators to produce speech.
- DECTalk (1984): The DECTalk, developed by Digital Equipment Corporation, was a significant advancement in TTS technology. It utilized a formant synthesis method and became popular in assistive technology.
- Natural Language Processing (NLP): Advances in natural language processing in the late 20th century enabled more human-like speech synthesis.
- Modern TTS Engines (2000s): Companies like Google, Amazon, and Apple introduced TTS engines with highly realistic and natural-sounding voices.
The Different Methods of Text to Speech Synthesis
Text to speech technology relies on various methods to convert text into speech. Some of the prominent methods include:
- Concatenative Synthesis: This method uses pre-recorded human speech segments to generate words and sentences. It offers high-quality, natural-sounding speech but can be limited by the number of available recorded segments.
- Formant Synthesis: Formant synthesis generates speech by modeling the physical properties of the human vocal tract. It’s versatile but may sound less natural.
- Articulatory Synthesis: This technique simulates the movements of the human articulatory system, producing highly customizable speech but requiring significant computational power.
- Statistical Parametric Synthesis: This method uses statistical models to generate speech, allowing for natural-sounding voices with less data required compared to concatenative synthesis.
The Challenges and Limitations of Text to Speech Technology
Despite its advancements, text to speech technology faces challenges:
- Naturalness: Achieving truly natural and expressive speech remains a challenge, particularly for longer texts.
- Emotion and Intonation: Capturing nuances of emotion and intonation in speech synthesis is difficult.
- Lack of Real-time Feedback: TTS systems may struggle with real-time feedback, such as pronouncing names correctly.
- Resource-Intensive: High-quality TTS often requires substantial computational resources.
- Language and Accents: TTS engines may perform better in some languages and accents than others.
The Future of Text to Speech Technology
The future of TTS technology holds exciting possibilities:
- Voice Personalization: More personalized and natural-sounding voices will become accessible, allowing users to customize the voices of their digital assistants and content.
- Emotional Speech: TTS systems will improve in conveying emotions, making interactions with AI and virtual assistants more human-like.
- Multilingual Capabilities: TTS systems will become more proficient in various languages and accents, increasing global accessibility.
- Education and Accessibility: TTS technology will continue to play a crucial role in education, accessibility, and assistive technology.
- Integration with AI: TTS will become an integral part of AI applications, enhancing user experiences.
Conclusion
The journey of text to speech technology from its early concepts to the sophisticated systems we have today is a testament to human ingenuity and the desire to make information more accessible. While challenges remain, the future of TTS technology promises more natural, expressive, and personalized voices, expanding its applications in education, accessibility, and everyday interactions. As TTS continues to evolve, it will undoubtedly shape the way we interact with digital content and AI-driven systems in the years to come.